
Looker Studio Text: String Manipulation, Matching & Numeric Properties
Data isn't always served to us on a silver platter. In the real world of analytics, especially when working with Looker Studio, you'll often encounter text data that's messy, inconsistent, or simply not in the format you need for your analysis. While we've all learned to manipulate numbers since childhood, working with text requires a specialized approach – and that's exactly what we'll explore in this article.
Today, we're diving into three powerful techniques for transforming your text data in Looker Studio:
Chaining functions for complex text transformations
String matching for categorizing your data
Extracting numeric properties from text
By mastering these techniques, you'll unlock new possibilities for data cleaning, analysis, and visualization in your Looker Studio reports. Let's get started!
Chaining Functions: Building Complex Text Transformations
One of the most powerful concepts in Looker Studio's calculated fields is the ability to nest functions within each other – what we call "chaining." This allows you to perform multiple operations on your text data in a single formula.
TRIM(): Removing Unwanted Spaces
Let's start with a common data quality issue: extra spaces in your text fields. These spaces might seem insignificant, but they can fracture your data and skew your analysis.
The TRIM() function removes both leading and trailing spaces from a text string. Here's how it works:
TRIM(City)
In this example, we're cleaning up city names that have unwanted spaces. Without trimming, " New York " and "New York" would appear as two separate entries in your reports, splitting metrics like revenue between them. After applying the TRIM() function, these variations are consolidated, giving you more accurate aggregated metrics.
Combining TRIM() with CONCAT() for Clean Names
Now, let's chain functions together to solve a more complex problem. Imagine you have first and last names in separate fields, and both might have unwanted spaces. You want to create a clean, full name field.
Here's the formula:
CONCAT(TRIM(First Name), " ", TRIM(Last Name))What happens here?
First, Looker Studio executes the innermost functions:
TRIM(First Name)andTRIM(Last Name)Then, it passes these cleaned values, along with a space character, to the
CONCAT()functionFinally, it returns a properly formatted full name with no unwanted spaces
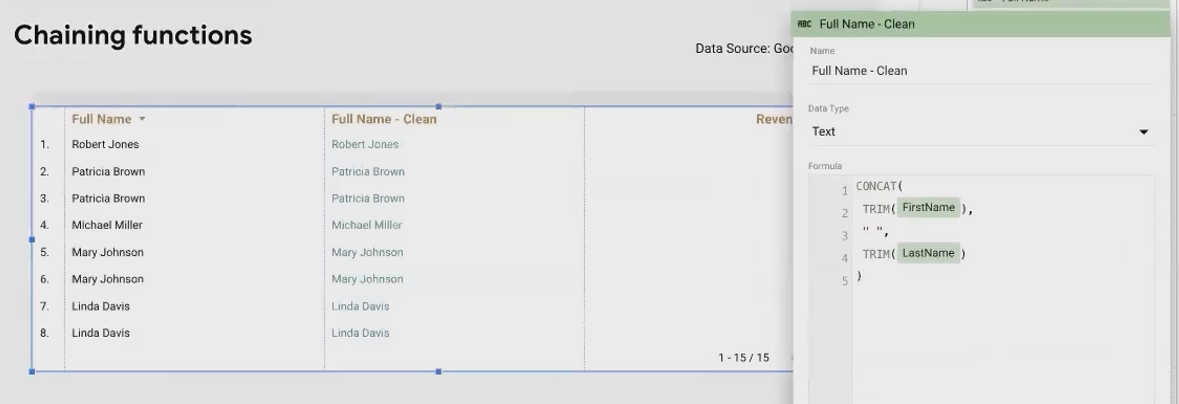
This is a simple example, but the concept of chaining functions is incredibly powerful. You can create complex data transformations by nesting various text manipulation functions within each other.
Pro Tip: When working with chained functions, build your formula incrementally. Start with the innermost function, test it, and then add the next layer. This makes debugging much easier if something goes wrong.
String Matching: Categorizing Your Text Data
Sometimes, instead of changing your text data, you want to categorize it based on certain criteria. This is where string matching functions come in – they analyze your text and return boolean (TRUE/FALSE) values that you can use to segment your data.
STARTS_WITH(): Analyzing Text Beginnings
The STARTS_WITH() function checks if a string begins with a specific substring. It returns TRUE if it does, and FALSE if it doesn't.
For example, if you're analyzing search queries for your website, you might want to identify all queries that begin with "looker studio":
STARTS_WITH(Query, "looker studio")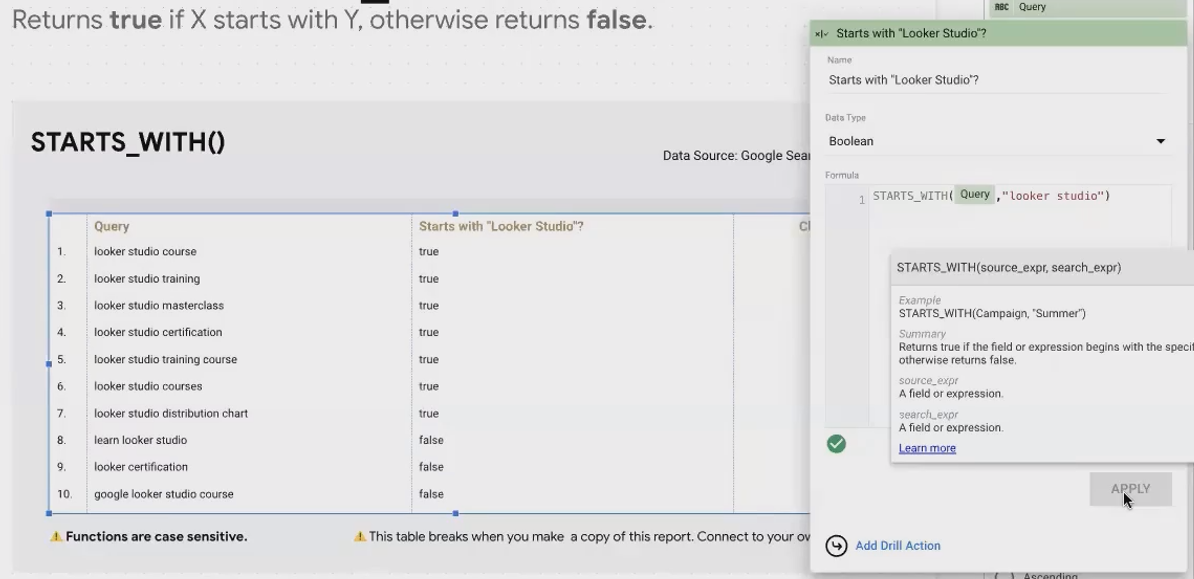
Important note: This function is case-sensitive! If your query contains "Looker Studio" with capital letters, but your formula uses lowercase "looker studio", it will return FALSE. To make your matching case-insensitive, you can combine it with the LOWER() function:
STARTS_WITH(LOWER(Query), "looker studio")CONTAINS_TEXT(): Finding Patterns Anywhere in Your Text
While STARTS_WITH() is limited to the beginning of a string, CONTAINS_TEXT() searches for a substring anywhere within your text. This makes it more flexible for categorizing data.
For instance, you might want to identify all search queries that mention "looker studio" regardless of where it appears:
CONTAINS_TEXT(LOWER(Query), "looker studio")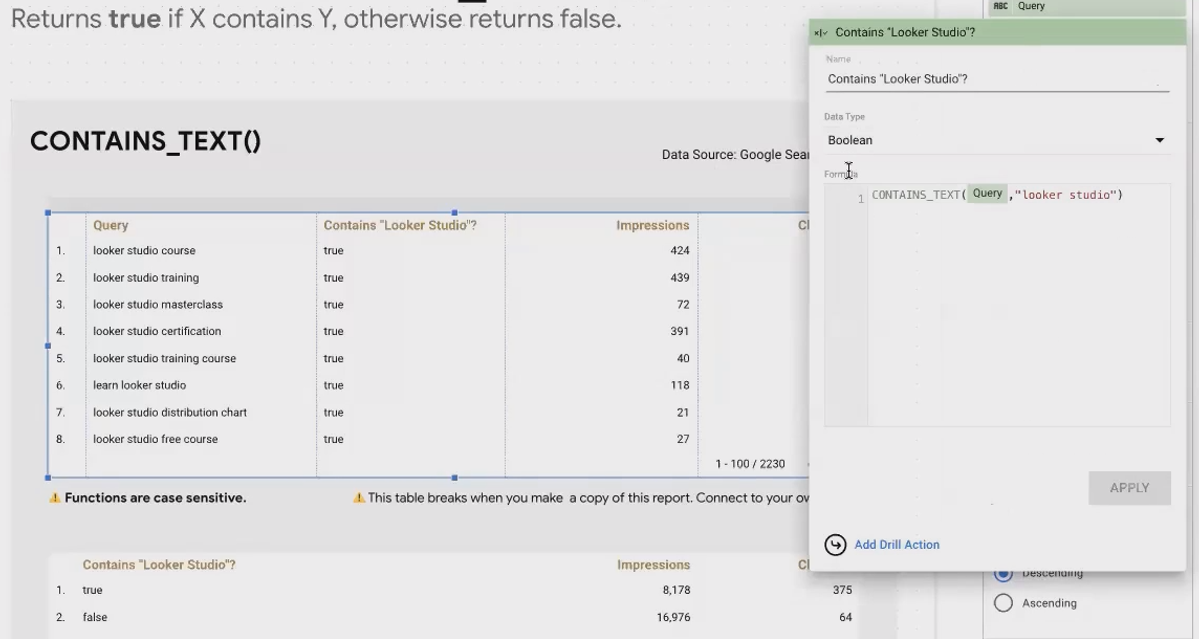
Once you've created these boolean fields, you can use them as dimensions in your charts to segment your data. For example, you could compare metrics for queries containing "looker studio" versus those that don't:
Remove the original text dimension (e.g., Query)
Use your boolean field as the dimension
View your metrics aggregated by TRUE/FALSE values
This approach allows you to analyze the performance characteristics of different text categories without getting lost in individual text values.
Real-World Application: You can use
CONTAINS_TEXT()to create a "Branded vs. Non-Branded" dimension for search queries. Define a formula that checks if queries contain any of your brand terms, and then analyze performance differences between these categories.
Counting & Numeric Properties: Deriving Numbers from Text
Text data contains valuable numeric insights if you know how to extract them. Looker Studio offers functions that take text as input and return numbers, opening up new dimensions for your analysis.
LENGTH(): Measuring String Length
The LENGTH() function simply counts the number of characters in a string. While this might seem basic, it enables interesting analyses.
For search queries, analyzing length can reveal patterns in user behavior:
LENGTH(Query)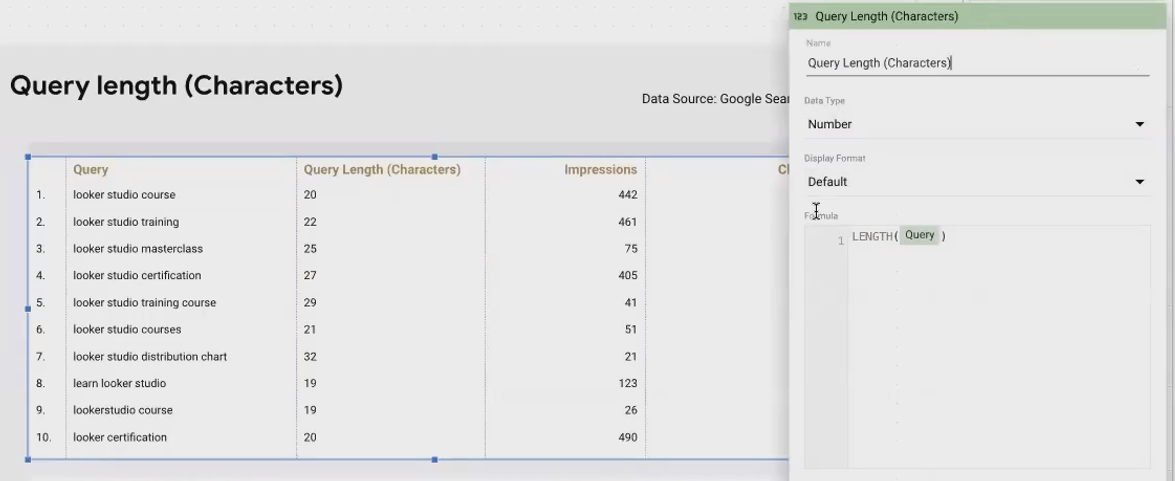
What makes this powerful is how you use the resulting numbers:
As a Dimension: Treat query length as a category to see how metrics like impressions or clicks vary by the length of queries. This can reveal sweet spots – perhaps medium-length queries (10-15 characters) drive more conversions than very short or very long ones.
As a Metric: Calculate the average length for different segments of your data. For example, what's the average length of queries that contain your brand name versus those that don't?
AVERAGE(LENGTH(Query))COUNT_DISTINCT(): Analyzing Unique Text Values
While not strictly a string function, COUNT_DISTINCT() is invaluable when working with text dimensions. It counts the number of unique values in a text field.
For example:
COUNT_DISTINCT(Query)This tells you how many unique search queries brought traffic to your site. You can also combine it with boolean fields from string matching to count unique queries in different categories:
COUNT_DISTINCT(Query) WHERE Contains_Looker_Studio = TRUE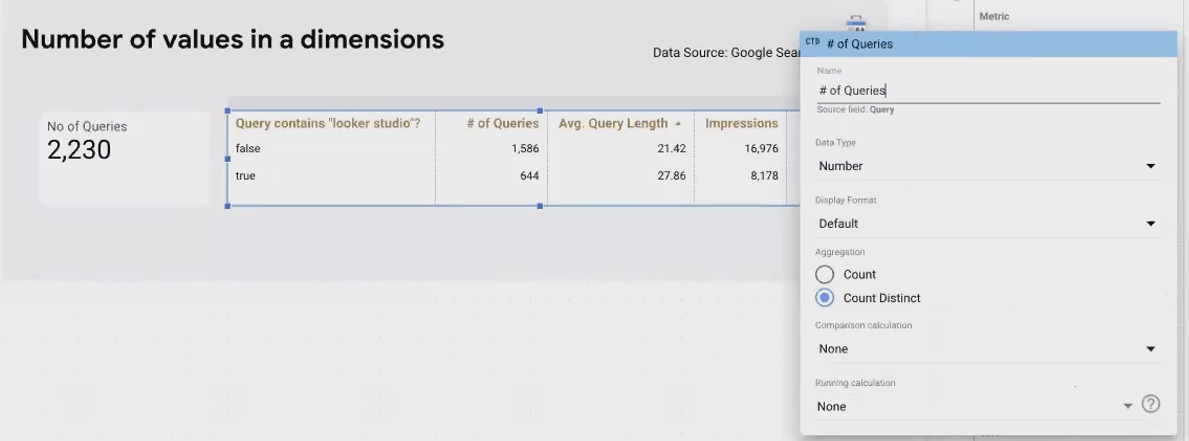
This approach helps you understand the diversity of text data within different segments of your analysis.
Frequently Asked Questions (FAQs)
Can I make string matching case-insensitive without using LOWER()?
For standard functions like STARTS_WITH() and CONTAINS_TEXT(), you'll need to use LOWER() to achieve case-insensitivity. However, if you're using RegEx functions like REGEXP_MATCH() or REGEXP_CONTAIN(), you can make them case-insensitive by adding (?i) at the beginning of your pattern, like: REGEXP_CONTAIN(Query, "(?i)looker studio").
Is there a limit to how many functions I can chain together in Looker Studio?
Yes, there is a limit to the depth of function nesting in Looker Studio, though Google doesn't specify the exact number. In practice, most complex transformations can be achieved with 3-5 levels of nesting. If you're hitting limits, consider breaking your transformation into multiple calculated fields, creating intermediate fields that feed into your final calculation.
How can I count words that match specific criteria, not just all words?
You can combine RegEx with conditional logic. For example, to count how many words in a text field contain "report", you could use:
LENGTH(REGEXP_REPLACE(LOWER(Text), "[^ ]*(report)[^ ]*", "X")) - LENGTH(REGEXP_REPLACE(LOWER(Text), "[^ ]*(report)[^ ]*", ""))This counts the difference in length between a string where matching words are replaced with "X" versus one where they're removed entirely.
Why do my string functions sometimes return unexpected results with international characters?
Looker Studio's text functions use UTF-8 encoding and should handle international characters correctly in most cases. However, some functions might treat certain special characters or diacritics differently than expected. For consistent results with international text, consider normalizing your text using a combination of LOWER() and REPLACE() functions to standardize special characters.
When should I use text length as a dimension versus a metric?
Use length as a dimension when you want to categorize your data by length ranges and see how metrics differ across these categories. Use length as a metric (with AVG aggregation) when you want to know the average length of text in different segments of your data. For example, "what's the average length of search queries that result in conversions versus those that don't?"
Text data holds a treasure trove of insights that go beyond simple categorization. By mastering function chaining, string matching, and numeric property extraction, you can unlock new dimensions of analysis in your Looker Studio reports.
Remember these key takeaways:
Chain functions to perform complex, multi-step text transformations
Use string matching to categorize your data based on text patterns
Extract numeric properties from text to quantify and analyze textual characteristics
These techniques will help you clean messy data, create more meaningful segments, and discover patterns that would otherwise remain hidden. As you grow more comfortable with text manipulation in Looker Studio, you'll find yourself creating increasingly sophisticated and insightful reports.
Note:
This post is based on a subject covered in the Looker Studio Masterclass Program. To learn more about Looker Studio Masterclass, click here.