
Master RegEx in Looker Studio: Your Guide to Text Transformation
Welcome to the exciting world of text transformation in Looker Studio! While many analysts excel at crunching numbers, a significant portion of your marketing data is actually text - URLs, campaign names, page titles, search queries, and more. Unfortunately, this text data rarely arrives in perfect shape. This is where Regular Expressions (RegEx) comes into play.
In this guide, we'll dive deep into using RegEx in Looker Studio - a powerful syntax for defining text patterns that allows you to manipulate and analyze text data with surgical precision. Whether you're trying to clean messy URLs, extract valuable information from text strings, or categorize content based on complex patterns, RegEx is your secret weapon.
Let's explore how these powerful functions can transform your Looker Studio reports from good to exceptional!
What is RegEx and Why Should Marketers Care?
Regular Expressions (RegEx) is essentially a language for working with text. Just as we have arithmetic operations for numbers (addition, subtraction, multiplication, division), RegEx gives us a syntax to describe, search for, and manipulate patterns in text.
For marketers and analysts, RegEx is particularly valuable because:
Data rarely arrives in the format you need it - RegEx helps you transform it
Text categorization can reveal powerful insights - Identifying patterns across thousands of entries
Dynamic text cleaning is essential - Remove or replace parts of text based on patterns rather than exact matches
Complex segmentation becomes possible - Create sophisticated segments based on text patterns
While basic string functions like CONCAT() or REPLACE() work for simple scenarios, RegEx offers unparalleled flexibility for complex text manipulation.
💡 Pro Tip: You don't need to be a RegEx master to get value from it. Focus on understanding the basics, learning how to test patterns, and knowing where to look when you need help. Tools like RegEx101 and even ChatGPT can help you build patterns for specific use cases.
Now, let's explore the RegEx functions available in Looker Studio!
REGEXP_REPLACE(): The Supercharged Find and Replace
Illustration: How REGEXP_REPLACE transforms text data
REGEXP_REPLACE() is like REPLACE() on steroids. Instead of replacing a static, exact string, it replaces text that matches a pattern you define.
Syntax:
REGEXP_REPLACE(text, pattern, replacement)Real-World Example: Cleaning URLs
One common challenge is removing query parameters from URLs. With standard functions, you'd need to know the exact query string to remove. With RegEx, you can dynamically remove any query string:
REGEXP_REPLACE(Page URL, "\\?.*", "")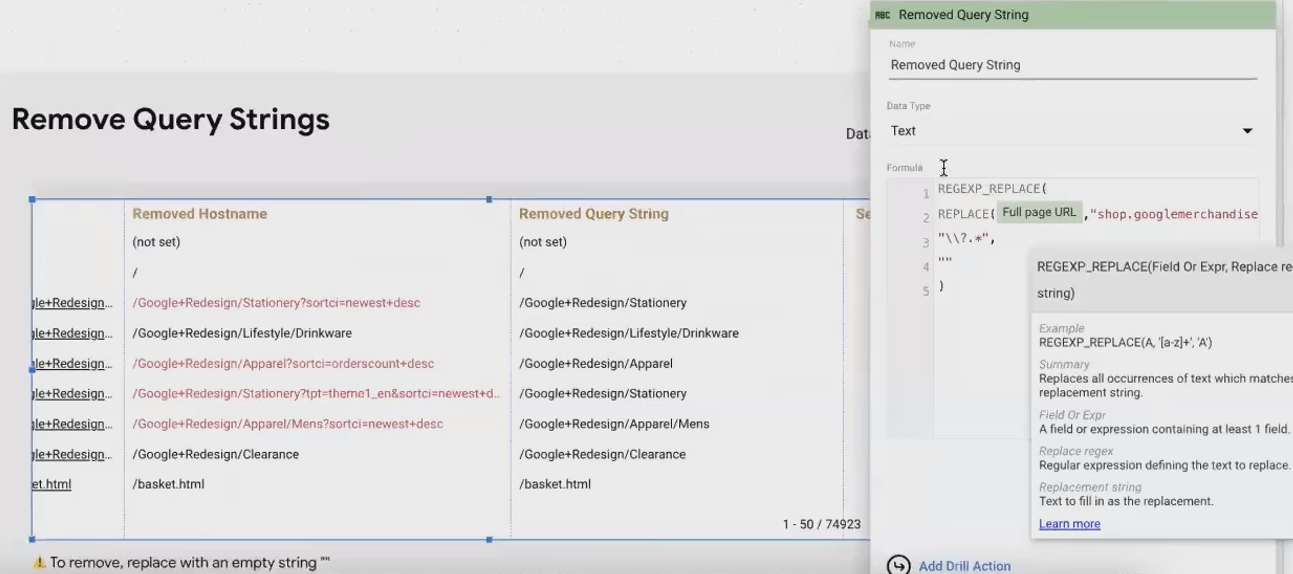
This formula finds a question mark (\? - escaped because ? has special meaning in RegEx) followed by any characters (.*), and replaces it with nothing - effectively removing query parameters from your URLs.
Example: Redacting Sensitive Information
Need to hide domain names in your reports? Instead of multiple REPLACE() functions for each domain, use:
REGEXP_REPLACE(Full URL, "[^/]+\\.[^/.]+\\.com", "[REDACTED]")
This pattern will match and redact domains like "shop.example.com" or "store.company.com" while preserving the rest of the URL.
Creative Example: Counting Words in Search Queries
Want to analyze how many words are in your search queries? Here's a clever approach:
Replace all non-space characters with nothing (leaving only spaces)
Count the spaces and add 1
LENGTH(REGEXP_REPLACE(Query, "[^ \\s]+", "")) + 1For "how to use looker studio" this would:
Replace each word with nothing, leaving only 3 spaces
Count the spaces (3) and add 1 = 4 words
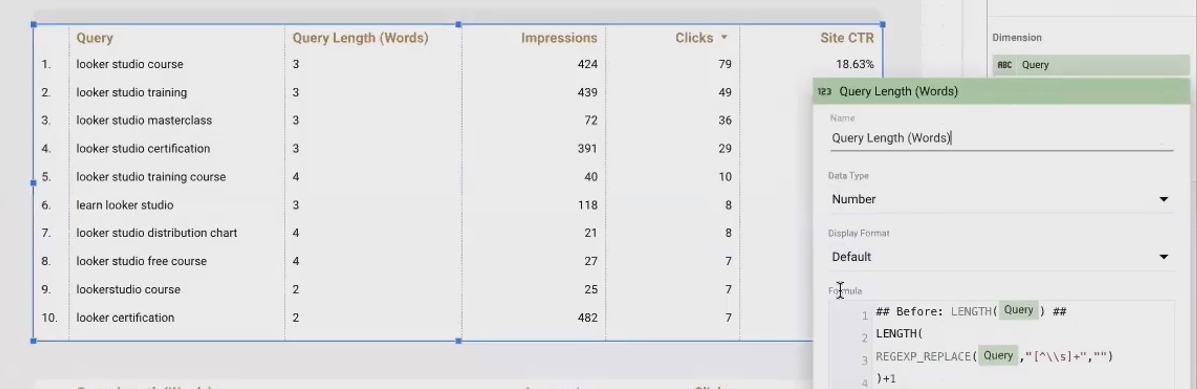
This technique lets you categorize and analyze queries by word count, which can reveal insights about user search behavior.
REGEXP_EXTRACT(): Pulling Out the Needle from the Haystack
When you need to pull out specific parts of a text string based on a pattern, REGEXP_EXTRACT() is your go-to function.
Syntax:
REGEXP_EXTRACT(text, pattern)The pattern should include parentheses () around the part you want to extract (a "capturing group" in RegEx terminology).
Example: Extracting Sort Parameters from URLs
Imagine you want to analyze which sort options users prefer on your e-commerce site. The URLs contain parameters like ?sort_ci=newest+descending:
REGEXP_EXTRACT(Landing Page + Query String, "sort_ci=([a-zA-Z0-9]+)")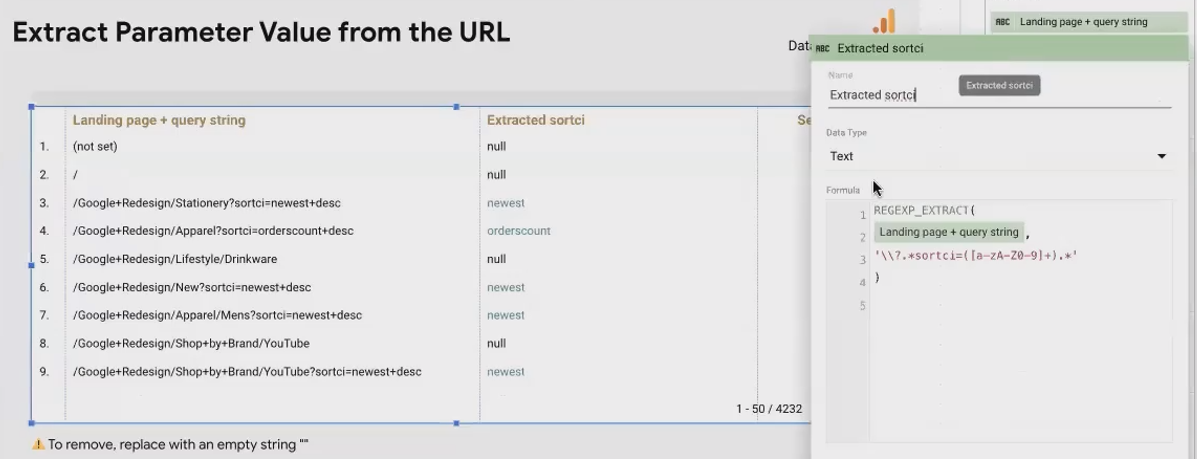
This would extract "newest" from the URL, allowing you to analyze the popularity of different sorting options.
Example: Extracting the First Directory from a URL Path
Want to categorize content by the top-level directory in your URL structure?
REGEXP_EXTRACT(Page Path, "^/([^/]+)/")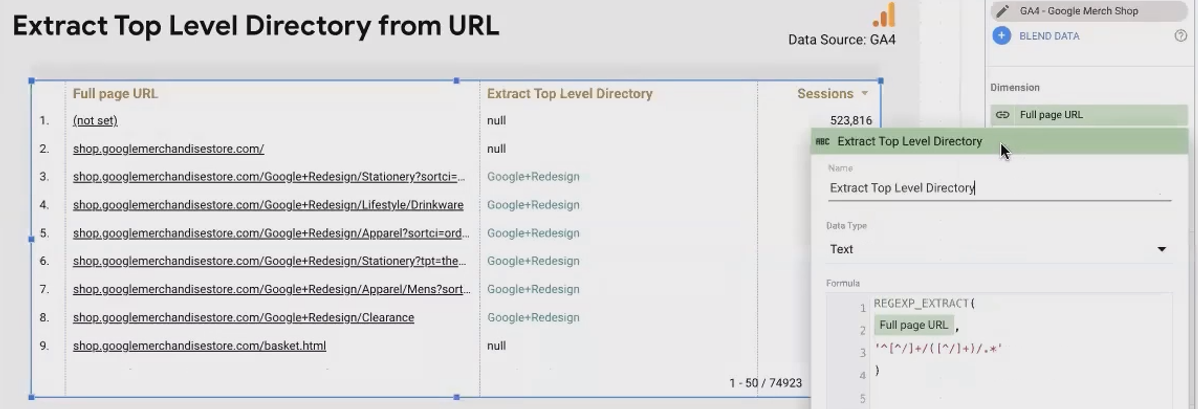
This pattern extracts the first directory after the domain. For "/products/shoes/nike", it would return "products".
According to a recent analysis of e-commerce sites, pages within certain top-level directories often have distinct performance patterns. With this extraction, you can identify which sections of your site drive the most engagement.
REGEXP_CONTAIN(): Finding Patterns Anywhere in Text
Sometimes you don't need to extract or replace text - you just need to know if a pattern exists within a string. REGEXP_CONTAIN() returns a TRUE/FALSE value when a pattern is found.
Syntax:
REGEXP_CONTAIN(text, pattern)Example: Identifying Question Queries
Want to segment search queries that are questions from those that are not?
REGEXP_CONTAIN(Query, "(?i)(how|what|why|where|who|which)")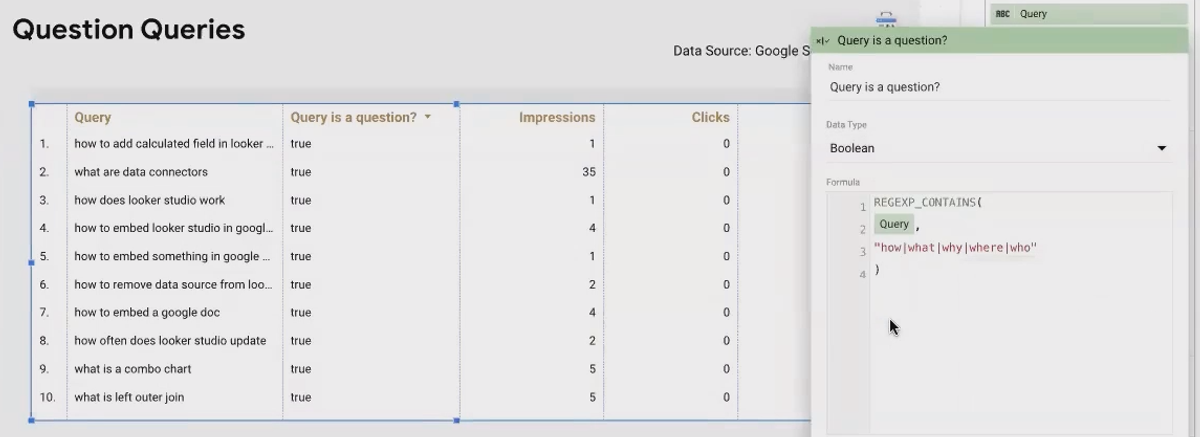
The (?i) makes the match case-insensitive, and the pattern looks for common question words. This returns TRUE for queries like "how to create a dashboard" or "what is data blending".
With this boolean dimension, you can:
Compare performance metrics for question vs. non-question queries
Identify content opportunities by analyzing question queries with high impressions but low clicks
Optimize your FAQ pages based on actual user questions
REGEXP_MATCH(): When Exactness Matters
While REGEXP_CONTAIN() checks if a pattern exists anywhere in the text, REGEXP_MATCH() verifies that the entire string matches the pattern exactly.
Syntax:
REGEXP_MATCH(text, pattern)Example: Identifying Specific Query Types
Let's say you want to identify "how to" queries that are exactly six words long:
REGEXP_MATCH(Query, "(?i)^how to ([a-zA-Z]+ ){5}[a-zA-Z]+$")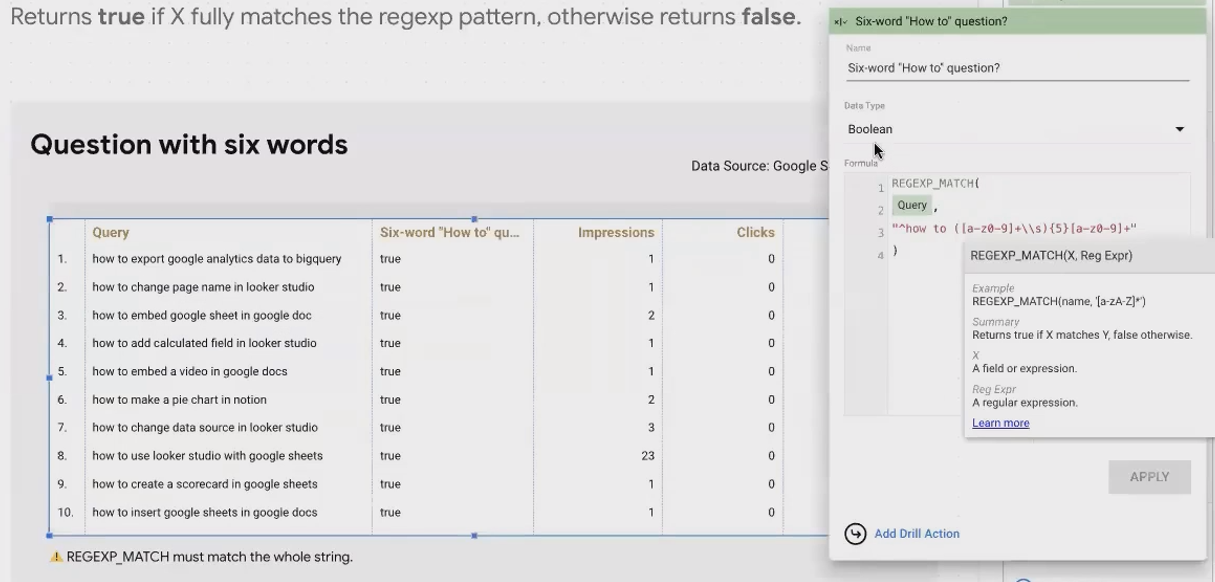
This would match "how to build a sales dashboard" but not "how to quickly build a sales dashboard" (7 words) or "how to build" (3 words).
This level of specificity allows you to:
Analyze performance based on query specificity
Identify patterns in high-performing queries
Target content creation to match successful query patterns
RegEx Flavors: Understanding RE2 in Looker Studio
Not all RegEx implementations are created equal. Looker Studio uses Google's RE2 engine, which has some key differences from other RegEx flavors you might be familiar with.
Key RE2 Characteristics:
Performance-focused: Designed to avoid "catastrophic backtracking" that can cause other RegEx engines to hang
Limited backreferences: Doesn't support features like
\1to reference earlier captured groupsNo lookaheads/lookbehinds: Features like
(?=...)or(?<=...)aren't supportedSyntax differences: Uses slightly different syntax for some operations
When testing your patterns on RegEx101.com or other tools, be sure to select the RE2 flavor for the most accurate results.
Essential RegEx Resources for Looker Studio Users
To help you on your RegEx journey, here are some invaluable resources:
RegEx101.com: An interactive tool for building, testing, and debugging RegEx patterns. Be sure to select the RE2 flavor.
Google's RE2 Syntax Documentation: The official reference for RE2, the flavor used in Looker Studio.
ChatGPT/AI Assistants: Excellent for generating and explaining RegEx patterns for specific use cases. Always test the generated patterns as they may need tweaking.
Looker Studio Community: Search for RegEx solutions others have already implemented for common challenges.
Frequently Asked Questions (FAQs)
How do I handle special characters in RegEx patterns?
Special characters in RegEx (like ., *, +, ?, [, ], (, ), {, }, ^, $, |, and \`) need to be "escaped" with a backslash if you want to match them literally. In Looker Studio, you often need double backslashes (`\\) because the first backslash escapes the second for the string processor, and the second escapes the special character for the RegEx engine.
For example, to match a literal question mark, use \\? in your pattern.
Can RegEx find whole words instead of just parts of words?
Yes! Use word boundaries (\\b) to match whole words. For example, \\bsale\\b would match "sale" but not "sales" or "wholesale". The pattern \\b asserts a position at a word boundary - a position where a word character is not followed or preceded by another word character.
How can I make my RegEx case-insensitive?
In RE2 (used by Looker Studio), you can add (?i) at the beginning of your pattern to make it case-insensitive. For example, (?i)looker would match "Looker", "looker", "LOOKER", etc.
What's the difference between .* and .*? in RegEx?
Both match any character (.) zero or more times (*), but they differ in greediness:
.*is greedy and matches as much as possible.*?is non-greedy (lazy) and matches as little as possible
For example, in the string "start-middle-end", the pattern start(.*)end would capture "-middle-", while start(.*?)end would capture the same. But in "start-middle-end-final", the greedy version would capture "-middle-end-", while the lazy version would capture "-middle-".
Are there any performance concerns with RegEx in Looker Studio?
While RE2 is designed to be efficient, complex RegEx operations on large datasets can impact performance. If you notice your reports loading slowly, consider:
Applying RegEx transformations at the data source level where possible
Simplifying your patterns when you can
Using non-RegEx functions for simpler operations
Regular Expressions might seem intimidating at first, but they're an incredibly powerful tool for any marketer or analyst working with text data in Looker Studio. The ability to transform, extract, and categorize text based on patterns unlocks analysis possibilities that simply aren't available with basic string functions.
Start small with one of the examples we've covered, test it on your own data, and gradually build your RegEx skills. Before long, you'll be creating sophisticated text transformations that turn messy data into valuable insights.
Remember - RegEx isn't about memorizing complex syntax; it's about knowing how to build patterns for your specific needs and where to find help when you need it. The investment in learning these fundamentals will pay dividends across your entire analytics workflow.
Note:
This post is based on a subject covered in the Looker Studio Masterclass Program. To learn more about Looker Studio Masterclass, click here.