
Looker Studio String Functions: Master CONCAT, LEFT_TEXT, LOWER & REPLACE
Ever notice how half your analytics data comes in text form? URLs, page titles, campaign names, user queries—all of these critical data points arrive as strings of text. Yet many analysts spend most of their time focused on numerical data while neglecting the wealth of insights hidden in text.
The truth is, text data rarely arrives in the perfect format you need. It's often inconsistent, messy, or lacks standardization. That's where string manipulation in Looker Studio becomes your secret weapon.
In this guide, we'll explore how to transform and wrangle text data directly within Looker Studio's data sources using calculated fields. We'll focus on four fundamental string manipulation functions that form the building blocks of text transformation:
CONCAT(): Merging text strings togetherLEFT_TEXT()&RIGHT_TEXT(): Extracting characters from either end of a stringLOWER()&UPPER(): Standardizing text caseREPLACE(): Swapping text patterns
By mastering these functions, you'll clean messy data, standardize inconsistent values, and unlock new dimensions for analysis that were previously hidden in your text data.
Let's get started!
String Manipulation: The Essential Toolkit
CONCAT(): Merging Text Strings
The CONCAT() function is one of the simplest yet most powerful text functions in Looker Studio. It allows you to combine multiple text strings into a single cohesive string.
How It Works
The basic syntax is:
CONCAT(text1, text2, text3, ...)
You can concatenate both field references (dimensions from your data source) and literal text values (static text in quotes).
Real-World Example: Creating Full URLs
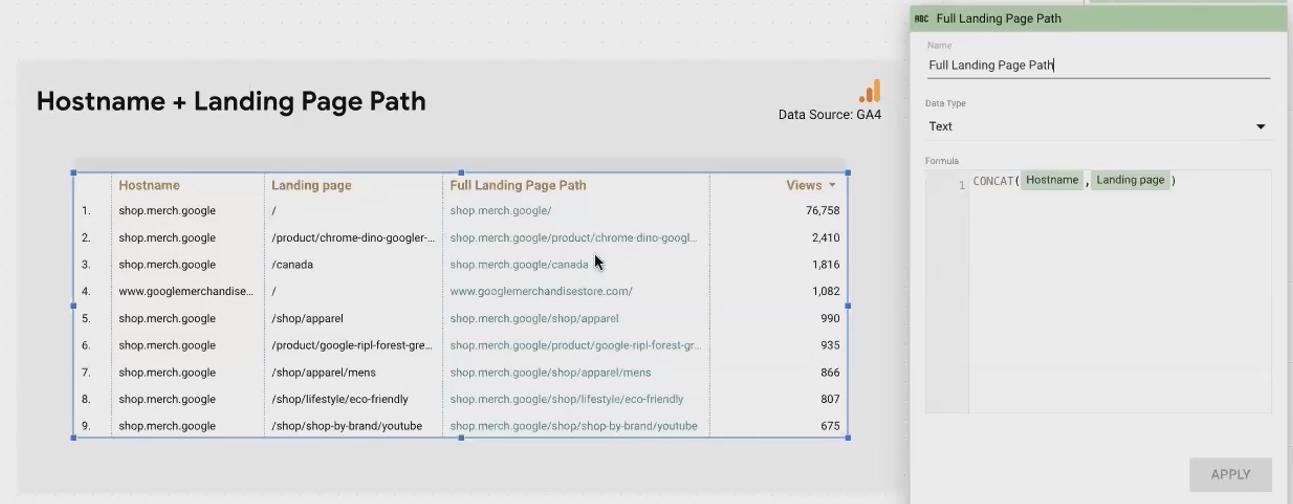
When working with Google Analytics 4 data, you'll often see that the hostname and page path are stored separately. To analyze the full URL, you need to combine them:
CONCAT(Host Name, Landing Page)This transforms:
Host Name: "shop.googlemerchandisestore.com"
Landing Page: "/google+redesign/apparel"
Into: "shop.googlemerchandisestore.com/google+redesign/apparel"
Real-World Example: Creating Full Names
When working with customer or employee data, first and last names are typically stored in separate fields. For reporting, you might want to display them together:
CONCAT(First Name, " ", Last Name)This combines:
First Name: "James"
Last Name: "Smith"
With a space between them: " "
To create: "James Smith"
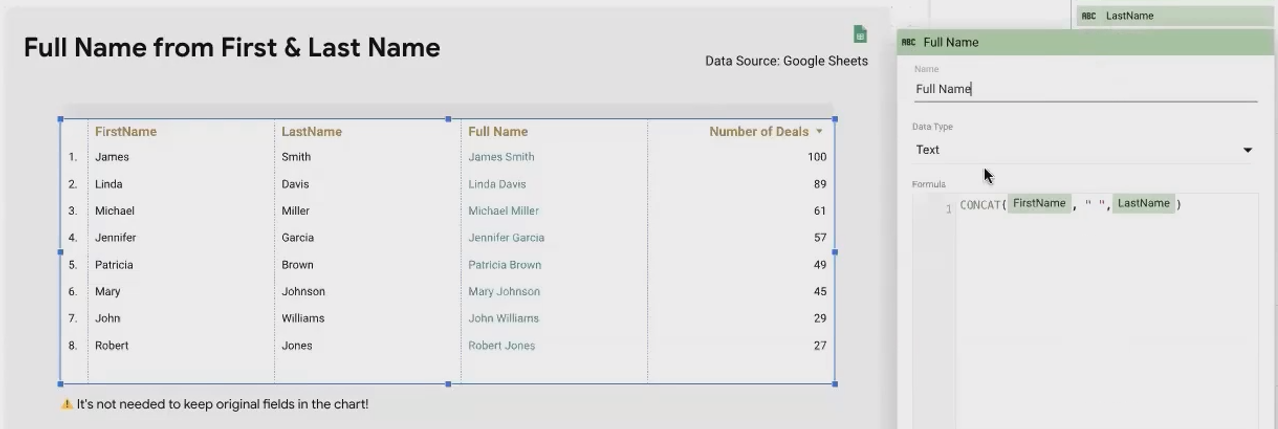
Notice how we included a literal space character between the quotes to ensure proper spacing between the names.
Pro Tip: After creating concatenated fields, you don't need to keep the original fields in your visualization. Remove them to create cleaner, more focused reports.
LEFT_TEXT() & RIGHT_TEXT(): Extracting Substrings
These functions allow you to extract a specific number of characters from either the beginning (LEFT_TEXT) or end (RIGHT_TEXT) of a string.
How They Work
The syntax is:
LEFT_TEXT(text, number_of_characters)
RIGHT_TEXT(text, number_of_characters)
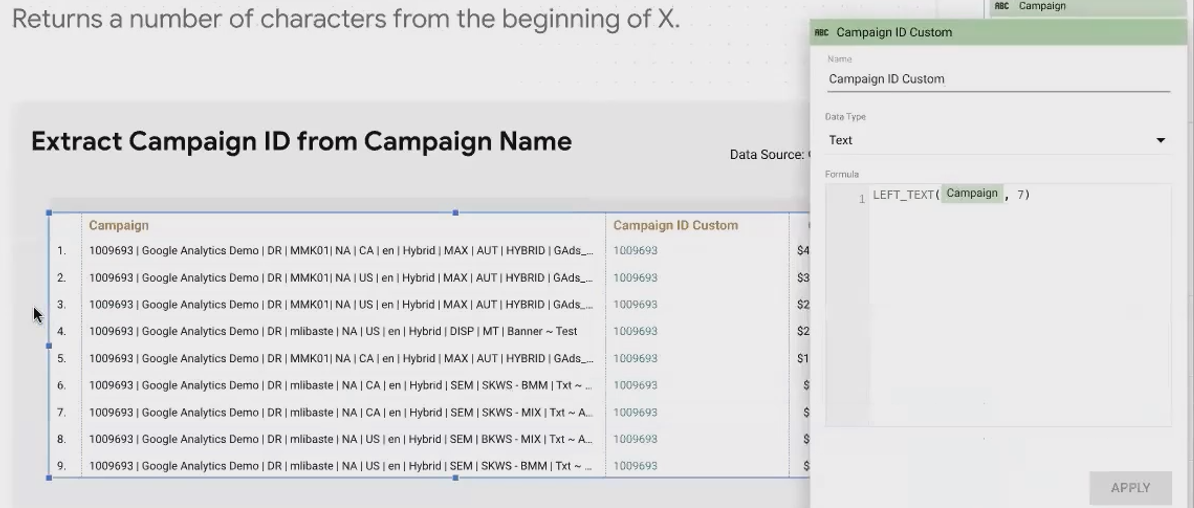
Real-World Example: Extracting Campaign IDs
Many marketing teams use consistent naming conventions for campaigns, like starting with an ID code. If your Google Ads campaigns always begin with a 7-digit ID followed by descriptive text:
LEFT_TEXT(Campaign, 7)This extracts "1234567" from "1234567 | Google Analytics Demo Campaign"
Creative Application: Email Redaction for Privacy
When sharing reports containing email addresses, you might want to mask portions for privacy:
CONCAT(LEFT_TEXT(Email, 4), "..redacted..", RIGHT_TEXT(Email, 7))This transforms "tameka.miller@example.com" into "tame..redacted..ple.com"
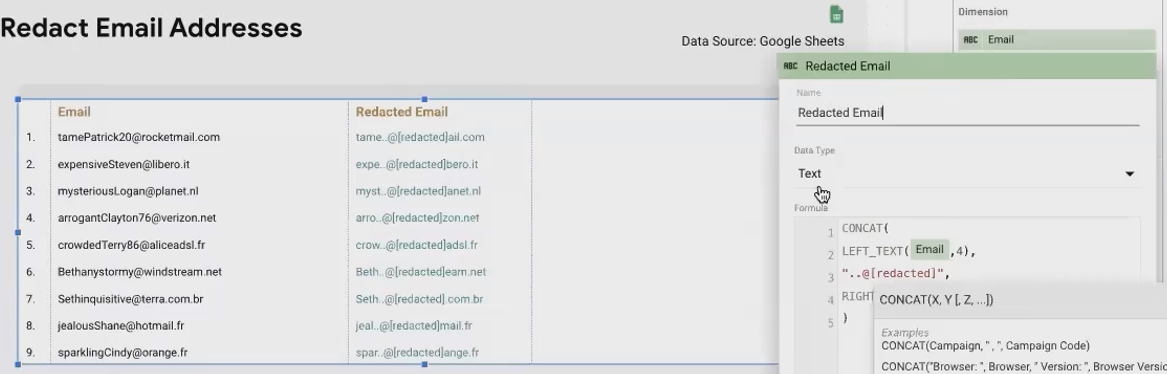
This technique maintains enough information to identify the email while protecting privacy in shared reports.
LOWER() & UPPER(): Standardizing Case
These functions convert all characters in a string to lowercase (LOWER) or uppercase (UPPER). They're crucial for data consistency and normalization.
How They Work
The syntax is straightforward:
LOWER(text)
UPPER(text)
Why Case Standardization Matters
Case sensitivity causes one of the most common data fragmentation issues. Without standardization, the same value might appear as multiple distinct rows:
"Facebook"
"facebook"
"FACEBOOK"
This splits your metrics across multiple rows instead of aggregating them properly.
Real-World Example: Source/Medium Standardization
In Google Analytics data, source/medium values often appear with inconsistent capitalization:
LOWER(Session source / medium)This standardizes values like:
"Newsletter"
"partners Affiliate"
"Google / cpc"
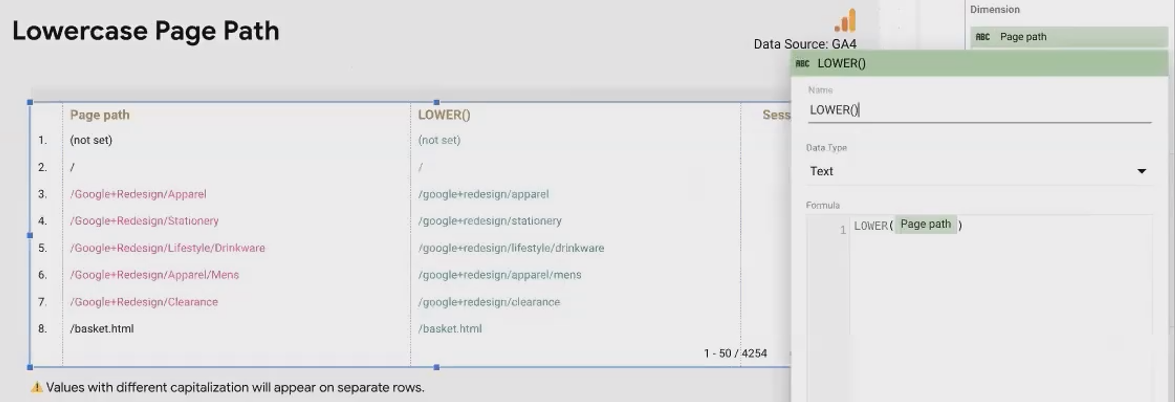
Into consistent lowercase versions, reducing your total number of distinct values and improving data aggregation.
According to a 2023 survey by the Data Quality Alliance, inconsistent capitalization accounts for approximately 15% of all data quality issues in marketing analytics platforms.
REPLACE(): Swapping Text
The REPLACE() function finds and replaces specific text within strings. It's perfect for data cleaning and standardization.
How It Works
The syntax is:
REPLACE(text, text_to_find, text_to_replace_with)Real-World Example: Hostname Redaction
When sharing reports externally, you might want to redact specific domain names:
REPLACE(Full Page Path, "shop.googlemerchandisestore.com", "[REDACTED]")This changes "shop.googlemerchandisestore.com/google+redesign/apparel" to "[REDACTED]/google+redesign/apparel"

Important Limitation
The REPLACE() function only works with static, exact matches. It cannot match patterns or variations. For example, it won't match:
"www.googlemerchandisestore.com"
"shop.googlemerchandisestore.net"
For more flexible pattern matching, you'll need to use RegEx functions like REGEXP_REPLACE(), which we'll cover in a future blogs.
Removing Values with REPLACE()
To remove text entirely, replace it with an empty string (""):
REPLACE(Full Page Path, "shop.googlemerchandisestore.com", "")This changes "shop.googlemerchandisestore.com/google+redesign/apparel" to just "/google+redesign/apparel"
Note: An empty string is represented by two quote marks with nothing between them (""), not a space between quotes (" ").
Frequently Asked Questions (FAQs)
When should I use string manipulation functions versus doing the same operations in my data source before importing to Looker Studio?
A: While pre-processing data is often ideal, string manipulation in Looker Studio offers several advantages:
No additional tools required - Transform data directly within your reporting tool
Real-time transformations - Changes apply immediately as data refreshes
Preservation of raw data - Original values remain untouched in your data source
Experimentation - Test different transformations without committing to permanent changes
Best practice is to handle systematic, large-scale transformations at the data source level, while using Looker Studio's functions for report-specific transformations and quick fixes.
How can I handle more complex text manipulations that these basic functions don't cover?
A: For more advanced text manipulation, Looker Studio offers Regular Expression (RegEx) functions:
REGEXP_REPLACE()- LikeREPLACE()but using pattern matchingREGEXP_EXTRACT()- Extract text matching a specific patternREGEXP_MATCH()andREGEXP_CONTAIN()- Test if text matches a pattern
These functions provide significantly more power and flexibility, allowing you to handle complex transformations like dynamic hostname redaction, query string removal, and pattern-based text extraction.
Do string functions in Looker Studio work with all data sources?
A: Most string functions work consistently across all data sources in Looker Studio. However, some data sources might have specific limitations with certain functions. For optimal performance, Google's own data sources (Google Analytics, Google Ads, Google Sheets, BigQuery) typically offer the most comprehensive support for all Looker Studio functions.
According to Google Cloud documentation, string functions in Looker Studio use the RE2 regex engine, which is the same engine used in BigQuery, ensuring compatibility across these platforms.
How do I chain multiple string functions together?
A: You can nest functions within each other to perform sequential operations. Looker Studio evaluates from the innermost function outward:
CONCAT(LEFT_TEXT(Email, 4), "..redacted..", RIGHT_TEXT(Email, 7))In this example:
First,
LEFT_TEXT(Email, 4)andRIGHT_TEXT(Email, 7)are evaluatedThen,
CONCAT()combines the results with the static text
Chaining functions is powerful but can make formulas harder to read. For complex transformations, consider breaking them into multiple calculated fields for better readability and maintenance.
String manipulation functions are essential tools for any Looker Studio analyst. They transform raw text data into standardized, actionable insights that drive better decision-making.
In this guide, we've covered the foundational functions—CONCAT(), LEFT_TEXT(), RIGHT_TEXT(), LOWER(), UPPER(), and REPLACE()—that form the building blocks of text transformation in Looker Studio.
By mastering these functions, you'll clean inconsistent data, create new meaningful dimensions, and extract hidden insights from your text data—all without leaving your reporting environment.
Remember that text data contains valuable insights waiting to be unlocked. Don't let messy strings stand between you and deeper analytics understanding!
In our upcoming blogs, we'll dive deeper into more advanced text manipulation techniques, including regular expressions (RegEx) and pattern matching, to unlock even more power in your Looker Studio reports.
Note:
This post is based on a subject covered in the Looker Studio Masterclass Program. To learn more about Looker Studio Masterclass, click here.